
以下の記事を書いていたらASCIIについても整理したくなったので、こちらにまとめました。
ASCIIコードとは
ASCIIコードとは英数、記号用の文字コードで、歴史とともにいくつかの派生が生まれた文字コードです。
基本部分は同じですが、いろいろと拡張されていく過程で複数の定義が生まれてしまいました。
「ASCIIコード」といっても、そこから派生したいくつもの規格があり、一部、互換性がない。これが悲劇の始まりでした。
ASCIIコード
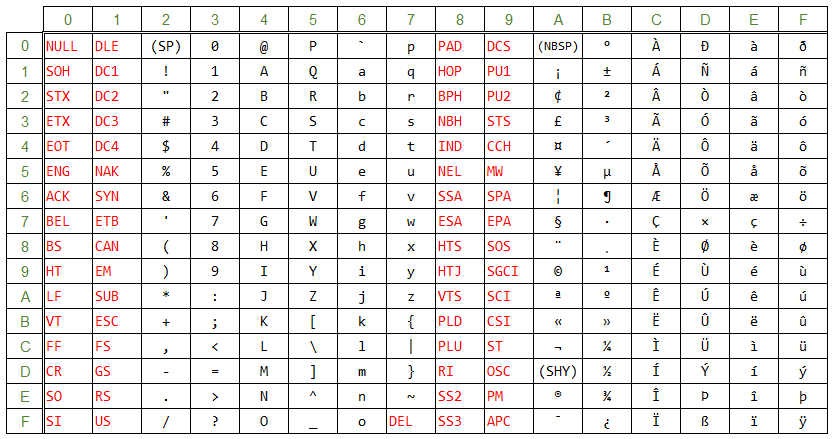
1963年に米国規格協会(ANSI)が定めた文字コードです。7ビットを単位としたコードで、7ビットで表せる0~127のコードに文字を割り当てた文字コードです。
「ASCIIコード」というと、これを指すことが正しいです。

この表の赤字部分である00~1F, 7Fは、文字ではなく機能が割り当てられているコードになります。機能とは、例えば、改行だったり、ビープ音を鳴らしたりです。一般に「制御文字」と呼ばれています。
7Fの「DEL」だけが、ほかの制御文字と離れた部分にあります。これには理由があって、昔はコンピュータのデータを紙テープに記録している時代がありました。
書き込むデータを2進数に変換して、2進数の「1」の部分に穴をあけていたわけです。例えば、「5B」というデータを書き込むとき、「5B」は2進数7桁では「1011011」なので、紙テープには「●〇●●〇●●」という感じで●に穴をあけていたのです。
ただ、これはオペレータが手で穴をあけていたので、当然、穴あけでミスをすることがあります。ミスをしても、一度開けてしまった穴はふさぐことができません。そんな時に、そのデータは誤りなので削除扱いにするために7Fの「DEL」に書き換えます。7Fは2進数で「1111111」なので、すべてに穴をあければいいのです。一度空けた穴はふさげないけど、全部に穴をあけることはできるので、7Fを「DEL」と定義したのです。
この時点では問題のないコード体系ですが、この先、ASCIIコードをベースとして「シフトJISコード」を定義するときに、この7Fが非常に厄介なものになることは、この時点ではだれも予測しなかったでしょう。
ISO 646
ASCIIコードはアメリカで策定された企画ですが、それを国際規格にしたものがISO 646です。規格化にあたり、ASCIIコードをベースにしつつも、一部、変更されています。
おそらく、この変更がASCIIコードの派生で最も罪深いものです。
ASCIIコードからの変更点は、国別に一部の文字に別の文字に割り当てることができることです。

赤枠で囲まれた部分の文字は、国ごとに別の文字を割り当てることができます。
日本では5Cの「\」(バックスラッシュ)が「¥」(円記号)に、7Eの「˜」(チルダ)が「‾」(オーバーライン)に変更されています。
プログラマーなら、開発環境やエディタによって「¥」が「\」に化ける経験があるのではないでしょうか。
ISO 646の問題は、同じエンコーディングを使用しても、それを表示する環境やアプリによって見た目が変わることです。
日本では変更されている文字が「\」と「˜」だけなので、まだマシな方で、デンマークになると多くの文字が変更になっています。特にプログラムで使用する文字が多く変更されており、以下のソースコードはデンマークの母国語の環境では見た目が大きく変わります。
public void something() { int[] n = {0, 1, 2}; }
public void something() æ intÆÅ n = æ0, 1, 2å; å
日本の「¥」問題なんてかわいく見えるぐらいの化け方です。
このようにISO 646はASCIIコードを国際規格に押し上げたのはよかったのですが、余計な仕様追加で混乱ののもととなりました。
ISO 8859
ASCIIコードは英数、記号用の文字コードとして誕生したため、各国固有の文字は収録されていません。例えば、フランス語などで使用されているアクセント記号付きのアルファベット(「Á」や「ô」など)は未収録です。
ISO 646で、一部の文字を差し替え可能になりましたが、差し替え可能な文字数が限られているうえ、差し替えた時の弊害が大きく、扱いづらいものでした。
そこで、ASCIIコードをベースにしつつ、各国で必要な文字を収録可能な文字コードが策定されました。それがISO 8859です。
ASCIIコードやISO 646は1文字を7ビットで表していましたが、1ビット拡張して、8ビットで1文字を表すようにしました。コンピュータはデータの最小単位をバイトで管理していることが多く、1バイトは8ビットなので、7ビットから8ビットになったところで大きな影響がなかったのです。
1文字8ビットにすることで、今までの倍である0~255の範囲を扱えるようになります。つまり、128文字分、新たな割り当て領域が生まれることになります。
しかし、128文字では、各国固有の文字をすべて収録することはできません。そこで、「部」という考えが生まれました。ISO 8859には第1部から第16部まであり(第12部は欠番)、それぞれの部はASCIIコード部分である0~127は共通の文字を割り当てますが、128~255は部によって、違う文字を割り当てています(一部、共通の文字はある)。
例えば、第1部は西ヨーロッパ言語圏で必要となる文字を収録したもので、次のようなコードになります。
16進数で80~9Fは、ASCIIコードの00~1Fと同様、制御文字に割り当てられており、A0~FFに文字が割り当てられています。
この80~9Fに割り当てられた文字は、ISO 6429という規格で定められた追加の制御文字です。つまり、ISO 8859は、ISO 646とISO 6429をベースに文字を追加した文字コードということになります。
| コードの範囲 | 収録文字の規格 |
|---|---|
| 00~7F | ISO 646で定められた文字 |
| 80~9F | ISO 6429で定められた制御文字 |
| A0~FF | ISO 8859で定められた部ごとの文字 |
次にキリル文字を収録した第5部を見てみます。

見ての通り、A0~FFに割り当てられている文字が大きく違います。
一見、ISO 8859はISO 646と同様、一部の文字を置き換え可能としたように見えますが、きちんと部というものを定義し、かつ、部ごとに割り当てる文字を定義しています。ISO 646のように「自由に置き換えてよい」ではないのです。
これによって、例えばISO 8859の第1部で作成されたテキストであれば、「ISO8859-1」という文字セットでエンコードすれば、文字化けすることなく、正しく表示できることになります。
ISO 8859は、規格を作った時代背景からすると、ベストな内容だったと感じます。当時のコンピュータで扱いやすい8ビットで1文字を表し、部を設けることで、いくつかの国の固有文字に対応、過去の規格をベースにしているので互換性もある。
しいて言えば、ISO 6429で定められた80~9Fの追加の制御文字を受け継ぐ必要があったのか、というのが疑問です。80~9Fを制御文字としてしまったことで、複雑怪奇なシフトJISを生んでしまいます。この話は別記事「シフトJISの悲劇」として、いつか書こうと思っています。
JIS X 0201
最後は、我が国日本におけるASCIIコードの派生文字「JIS X 0201」です。
ISO 8859はいろんな国固有の文字を「部」として規格化しましたが、残念ながら日本語固有の文字は規格化されませんでした。
そこで、日本は独自にASCIIコード(正しくはISO 646)をベースに日本語固有文字を追加したJIS X 0201規格を作りました。
日本語固有文字といっても、8ビットで「ひらがな」「カタカナ」「漢字」をすべて収録することは不可能なので、「カタカナ」のみの収録となりました。

ISO 8859と同様、A0以降に「カタカナ」を割り当てています。E0~FFが未割当ですが、残念ながら「ひらがな」を収録できるだけのスペースでもないので、「カタカナ」のみの収録にとどまりました。
悪名高き「半角カタカナ」誕生の瞬間です。
JIS X 0201も、ISO 8859と同様、当時のコンピュータ事情を考えると、それほど悪い規格ではありませんでした。
そして、多バイト文字の時代へ・・・
ASCIIコードと、その派生文字は、当時のコンピュータの処理能力から、1バイト(= 8ビット)で1文字を表すものでした。
しかし、コンピュータの処理能力が上がっていき、漢字混じりの日本語が使いたい、という需要が出てくると、1文字を2バイトで表す「シフトJIS」が出現し、各国でもいろんな文字コードが生まれ、文字コードを統一しようという動きから、現在のUnicodeの誕生に至ります。
この様々な文字コードが誕生する過程でも、ASCIIコードが生んだ悪い部分が影響していて、コンピュータ業界の「負の遺産」を背負い続ける宿命が垣間見れます。
では、次回「シフトJISの悲劇」でお会いしましょう。