前回の「ASCIIコードの悲劇」では、ASCIIコードとその派生コードの生い立ちを書きましたが、今回は、「JISコード」、とりわけ「シフトJISコード」について説明します。
前回の「ASCIIコードの悲劇」で「JIS X 0201」を紹介しました。この「JIS X 0201」も日本産であるJISコードファミリーの一員なのですが、1バイトで1文字を表現したため、使える日本語はカタカナのみでした。
しかし、コンピューターが普及するにしたがって、ひらがなや漢字など、日本語全般を扱う需要が高まり、それに伴い、日本語全般を扱える文字コードが規格化されました。
JISコード
半角カタカナしか扱えない「JIS X 0201」もJISコードの一つですが、JISコードファミリーの中では知名度が低く、JISコードというと、日本語全般が使えるJISコードを指すことが多いです。
そして、日本語全般を扱えるJISコードも、実は多様な種類があります。ここでは、JISコードの種類ごとの説明は省略します。いろんな種類がありますが、種類というよりは、時代とともに扱える文字が増えた規格ができた、と思えばよい程度です。
このJISコードは、初めは日本国内だけのローカル規格でしたが、のちに、国際標準化機構(ISO)により、「ISO-2022-JP」と名前が付けられ、国外でも通用する規格になりました。広義では「JISコード」=「ISO-2022-JP」です。
ちょっと前置きが長くなりましたが、次にJISコードの構造です。
日本語は、漢字だけで10万字をこえるといわれています。当然、これらの文字をすべて扱うには当時のコンピュータでは無理ですし、そもそも、すべての文字を扱う需要があったわけではありません。
そこで、よく使用される常用漢字に絞った規格としてJISコードが作成されました。
初めにJISコードの英数記号部分です。
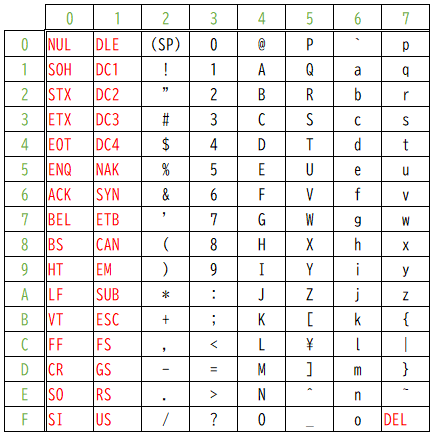
21~7Eに文字がマッピングされてます。
ASCIIコードと同じですね。そうです。コンピューターの世界では、互換性が大切なので、過去の規格をベースに新しい規格が作られるのです。
次に、JISコードの半角カタカナ部分です。
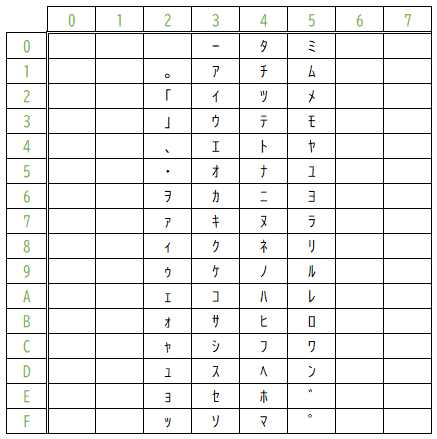
21~5Fに文字がマッピングされています。
ここで、「あれ?」と思ってほしいです。
半角の「A」は16進数で41にマッピングされていますが、半角カタカナの「チ」も41にマッピングされています。前にも述べたとおり、ファイルは「数値」の集合体です。これではテキストファイルに「41」という数値が書き込まれていた時に、それが「A」を表すのか、半角カタカナの「チ」を表すのかがわかりません。
謎は残りますが最後に全角文字(記号とかひらがな、カタカナ、漢字)の一部分を見てみます。
全角文字は2バイトで1文字を表します。例としてひらがな部分を上げます。ひらがなは16進数「24」+「21~73」の2バイトで表されます。

ひらがなの「ち」であれば、16進数で「24」+「41」となります。
またまた、「あれ?」です。16進数の「24」+「41」は、ひらがなの「ち」を表しますが、半角の「$」+「A」も表しますし、半角カタカナの「、」+「チ」も同じです。
これまでのコード表を見てもわかるように、JISコードは、文字を16進数の21~7Eの範囲にマッピングしています。つまり半角文字は7ビット、全角文字は2組の7ビットで表すのです。
しかし、7ビット部分はすでにASCIIコードで使用されています。互換性を維持するために、これは動かせません。ではJISコードではどうしたか?というと、「使われているなら仕方ない。同じところに違う文字をマッピングさせよう」となったのです。
これは、「ASCIIコードの悲劇」で説明した「ISO 8859」の「部」の考え方に似ていますが、「ISO 8859」では、一つのファイル内で複数の「部」が混在することはありません。
それに対し、日本語では、一つのファイル内に半角の英数、カタカナ、全角文字のすべてを混在させる必要があります。例えば、プログラムコードであれば、コードは半角の英数記号で記述しますが、コードコメントには漢字とかひらがなを使いたいですよね。
この混在使用を実現するために、シフトイン・シフトアウトという考えが必要になります。簡単に言うと、文字種が切り替わる境目に、「ここからは全角です」とか「ここからは半角です」というマークを挟むのです。
例として「私はTOMです.」というテキストをJISコードで表現したときのコード列を見てみます。

全角文字の前に、「ここからが全角」であることを表す「Kanji in」があり、半角文字に切り替わるところでは、「ここからが半角」であることを表す「Kanji out」があることがわかります。
「Kanji in」は16進数で「1B 24 42」の3バイト、「Kanji out」は16進数で「1B 28 4A」の3バイトで表されます。
当然、「Kanji in」と「Kanji out」はマークであって、文字ではないので、テキストエディタなどでは視認することはできません。また、どちらも1バイト目は制御文字「ESC (1B)」で始まっています。
以前の記事で、テキストファイルの定義は「テキストファイルは「文字」と「改行」、「タブ」にあたる数値の集まりである」と説明しましたが、JISコードのファイルに限っては、「テキストファイルは「文字」と「改行」、「タブ」、「Kanji in」、「Kanji out」にあたる数値の集まりである」となります。
このコード例を見てもわかる通り、JISコードは適宜「Kanji in」、「Kanji out」を挟む必要があり、ファイルのサイズが大きくなり、かつ、ファイルの読み書きのロジックが複雑になることがわかります。
シフトJISコード
すでに規格化されているJISコードは「Kanji in」、「Kanji out」のため、複雑なコードになってしまい、非常に扱いずらいものでした。
他のコードでは単純に、文字コードに対応する文字を表示するだけでよいのですが、JISコードは「全角文字中」なのか「半角文字中」なのかという、いわゆる「状態」に応じて、同じコードでも表示する文字を切り替える必要があります。
そこで、今回の主役「シフトJISコード」の登場です。
シフトJISコードは、コンピューターで扱いやすいよう、次のような特徴を持ちます。
- すべての半角文字は1バイトで表す。
- すべての全角文字は2バイトで表す。
- シフトイン、シフトアウトのような文字種の切り替えはなく、コードに対応する文字は1つのみ。
当時のコンピューターは、半角文字(1バイト)の2文字分の幅で全角文字(2バイト)を表示していたので、画面に表示されている文字幅とバイト数が一致していることからも、分かりやすい文字コードでした。
では、シフトJISコードのコード体系を見ていきます。
まずは半角文字部分です。

どこかで見たことがありませんか?そうです。以前にASCIIコードを拡張して半角カタカナを追加した「JIS X 0201」とほぼ同じコードマッピングです。違いといえば、ほとんど使用されない拡張制御コード部である「80~9F」を未定義としました。
これにより、シフトJISコードは半角部分で過去の「JIS X 0201」との互換性を確保したことになります。
次に全角部分です。
全角文字は2バイトで1文字を表し、かつ、半角文字と同じコードを共有しない必要があります。
先ほどの半角文字のコード表を見るとわかる通り、80~9F、E0~FFが未使用なので、全角文字はこの範囲のコードが使えます。
ただ、80~9F、E0~FFの範囲のコードは64種です。全角文字は2バイトなので、64×64=4096種のコードが使えることになります。しかし、4096種では、常用漢字にあたる6千字を超える文字を表現するには足りません。
そこでシフトJISでは、全角部分の1バイト目は半角部分とコードを共有しない81~9F、E0~EFの47種とし、2バイト目は半角部分とコードを共有する40~7E、80~FCの188種を使用することとしました。
全角1バイト目で使用するコード

全角2バイト目で使用するコード

これにより、1バイト目の47種 × 2バイト目の188種 = 8836種の文字を2バイトで表現できることになります。
2バイト目が半角文字と同じコードを共有していますが、1バイト目が全角文字を示す81~9F、E0~EFの範囲であれば、次のバイトは全角文字の2バイト目として扱えばよいので、比較的簡単な判断ロジックで半角文字と全角文字を扱うことができます。
シフトJISの悲劇
シフトJISコードは、JISコードと比較して扱いやすかったため、日本のコンピューターでスタンダードの地位を築き上げます。
しかし、コード体系を見てもわかる通り、いくつかいびつな個所があります。
1バイト目の悲劇
81~9F、E0~EFと2つのコード範囲に分割されてしまいました。
これは、JIS X 0201で半角カタカナをマッピングするときに、ISO 8859のマッピングに従い、80~9Fを拡張制御コードに割り当てたためです。
ISO 8859が拡張制御コードを継承せず、追加の文字をコード80からキレイに割り当てていれば、このように空きコードが分断されることはなかったでしょう。
2バイト目の悲劇
40~7E、80~FCと2つのコード範囲に分割されてしまいました。
これは、分断の原因となった7Fに制御文字「DEL」が割り当てられているためです。
制御文字「DEL」だけがほかの制御文字00~1Fとは離れた場所に定義された経緯はASCIIコードの悲劇で説明しています。
当時の背景を考えると、7Fに制御文字「DEL」が割り当てられたことは仕方がありませんし、後世でこのような弊害を生むとは想像がつかなかったでしょう。
ASCIIコードが初めから8ビットで定義されており、制御文字「DEL」が8ビットの最終コードであるFFに割り当てられていれば、この悲劇は生まれなかったはず。非常に残念です。
コード5Cの悲劇
シフトJISコードでは、2バイト目にコード「5C」が含まれる可能性があります。
このコード「5C」が一部のプログラム言語では非常に厄介な問題となります。
コード「5C」はASCII文字でいう「\」にあたります。この時点でピンと来た人もいるでしょう。シフトJISの2バイト目がコード「5C」になる文字の場合、2バイト目を「\」と認識して、次の文字をエスケープする可能性があります。
例えば、C言語で画面に「表n」と表示するために、次のようなコードを書いたとします。
printf("表n");
しかし、このコードは期待通りの動きになりません。「表」の文字コードは「95 5C」あり、2バイト目が「¥」なのです。そして「表」の次に「n」という文字があるので、「\n」と認識され、改行されてしまいます。
C言語で画面に「表n」と表示したい場合、次のように「\」を余分に追加して、エスケープ文字をエスケープする必要があります。
printf("表\n");
この「\ (5C)」以外にも、パイプ文字「| (7C)」が問題となるプログラム言語もあり、全角文字の2バイト目を半角文字のコードと共有したことが問題となるケースが多くあります。
これらのように、全角文字の2バイト目が、半角文字のエスケープ記号など、ある特定の意味のある文字の場合に問題となる文字を一般的に「ダメ文字」と呼称されています。
シフトJISコードまとめ
シフトJISコードもほかのコードと同様、過去のコードとの互換性を保ちつつ、拡張したコードでした。
そのため、全角文字は1バイト目、2バイト目ともにコードが連続せず分断した不格好な形となった。2バイト目を半角文字のコードと共有したためにダメ文字が生まれた。と問題が出ました。
過去の互換性を保つためには仕方のない範囲でうまく規格化されているので、いまいちな点はありますが、シフトJISを否定する記事ではありません。むしろ、制約のある中でうまく規格化した文字コードである、ともいえるものです。
そしてUnicodeへ...
シフトJISコードは日本でスタンダードな地位を築くとともに、いろいろな派生コードを生み出すことになります。
NECが追加した「NEC特殊文字」、IBMが追加した「NEC選定IBM拡張文字」、Microsoftが拡張して、のちにWindowsで標準化された「Windows-31J」など、細かい部分で違いがある複数のシフトJISコードが出てきます。
シフトJISコード以外に、Unixで日本語文字を扱うために生まれたEUCコードや、古くからホストコンピューターで使用されているEBCDICコードなど、日本だけでも複数のコードが乱立し、プログラマは文字コードの変換に多くの手間を割くことになります。
そして、日本以外の国でも同様に、母国語用に独自の文字コードが規格化されており、コンピューターの文字コードは混とんとした時代を迎えます。
誰もが、「文字コード面倒。どうにかならんものか」と思っていましたが、「世界で使われるすべての文字を一つの文字コードで扱えるようにしよう」という統一規格が立ち上がります。それがUnicodeです。
Unicodeは、全世界の文字コードが一つの文字コードに統一されるという、壮大な計画です。今なお成長し続けているUnicodeは、素晴らしいもになるはずでした...